编者按:精准医疗时代下的临床研究发生了许多改变,对科研工作者也提出了新的要求。在2016年12月17日由中国临床肿瘤学会和北京市希思科临床肿瘤学研究基金会主办、同济大学附属东方医院承办的“2016 CSCO—东方肿瘤精准医学论坛”上,浙大一院肿瘤细胞生物治疗中心主任方维佳教授深入阐释了精准医疗背景下的科研数据管理,下面请随我们一起一睹为快吧!
精准医疗背景下,临床研究的演进
一般来说,临床研究数据可以分四个层级:第一层是系统级数据,例如消化系统、呼吸系统等系统功能障碍等的病例数据;第二层是器官级数据,包括患者的B超、X片、部分症状与体检、部分检查报告等;第三层是细胞级数据,包括标志物、部分实验室检查、病理分析等;第四层也是最底层、最基础的数据——基因级数据,即基因测序的相关信息等。
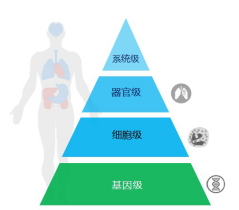
在精准医疗的时代,数据被层层分级,同时,我们对科研数据的处理方法也在逐渐演进中。首先是研究方法的改变,即从“小随机”到“大数据”,这种演进的核心基础在于符合医学标准的数据结构化。“大数据”的研究方法涵盖了传统的统计分析、数据挖掘和人工智能/机器学习。数据管理的模式也在改变,即从“单课题数据库”到“科室数据中心”。由于数据科技在不断发展,我们要从本质和整体角度探究肿瘤,尽可能采集不带假设条件的医疗信息,包括临床数据、生物样本信息、分子遗传信息等。其中,临床数据的来源有系统级、器官级、细胞级;生物样本信息的来源有器官级、细胞级;而分子遗传信息的来源则是细胞级和基因级。
科室数据中心建设的思考
关于科室数据中心的建设,首先应考虑的问题是:单课题研究的数据结构太过简单,因为单课题研究都以研究目录为中心,考虑特定人群、标准条件、短期数据等,但大部分的肿瘤患者未被任何单课题研究纳入。
单课题研究的数据管理包括信息记录、实验数据和统计分析。信息记录又包括:入组样本信息、本次研究观察指标等;实验数据包括:实验条件、该条件下实验室或临床结果;而统计分析包括:传统的生物统计学方法、生物信息学方法。
基于单个课题的多中心临床试验,由不同研究者依据同一标准开展合作研究的方法得到现代循证医学的充分认同.其研究成果也成为深刻影响肿瘤诊治理念和标准的各种指南和规范。就本质而言,多中心临床试验是数据共享的具体形式之一,也为肿瘤研究的大数据时代开启了探索之路。不同的是.临床试验多围绕特定的研究目的进行设计和规划,其数据资料主要为该研究服务。因此,在数据的全面性上可能存在一定的狭隘性。
第二个问题是“大样本数据对精准医疗有何价值?” 在我看来,无论是“临床大数据”还是“生物大数据”,这些大数据构成的“有效知识”是肿瘤疾病知识库,也是精准医疗的基础。这里涉及到一个“生物医学研究知识网络”的概念,该知识网络包括患者的基因组数据、转录组数据、蛋白组数据、代谢组数据、生理组数据、病理组数据等,这些数据在共享平台上构成了一个信息网络。
精准医疗背景下,研究方法从小随机到大数据的改变,对临床数据的处理过程将提出更高的要求。这里给大家分享两个案例——即“雨伞试验”和“篮子试验”,它们都是伴随基因测序技术普及而来的新研究方式,足以体现出大数据对精准医疗的价值。
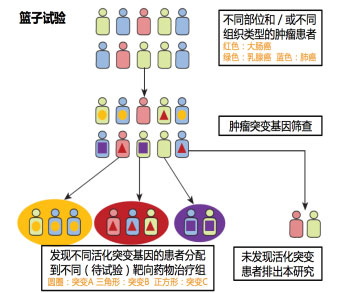
什么是“篮子试验”? 如下图所示,我们纳入不同部位、不同组织类型的肿瘤患者,对他们进行肿瘤突变基因的筛查,发现A、B、C三种突变型,然后将不同活化突变基因的患者分配到不同(待试验)靶向药物治疗组中,将未发现活化突变患者排出本研究,这就是篮子试验的模型。
什么是“雨伞试验”?即纳入相同部位或组织类型的肿瘤患者,对他们进行肿瘤突变基因的筛查,发现A、B、C三种突变型,将不同活化突变基因的患者分配到不同(待试验)靶向药物组,每个靶向药物组中患者再随机分为治疗组和对照组,未发现活化突变基因的排出本研究,这就是雨伞试验的模型。

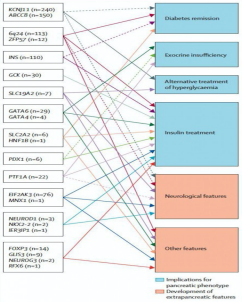
“雨伞试验”与“篮子试验”还可以相结合,如下图展示的是儿科及内分泌科的临床医生绘制的一幅由大量的Umbrella和Basket组成的图谱,我们姑且称之为“伞篮图”,伞篮试验为精准治疗的实践提供了有利佐证。 雨伞的顶端是左侧列举的22个与新生儿糖尿病发病相关的基因,篮子的底部是右侧6个对临床诊疗和预后判断具有显著影响的临床表现。一旦出现这些临床表现,应立即采用基因测序的技术明确致病基因,并制定相应的临床诊疗方案。未来,大量的疾病诊治将遵循这样的基于海量基因组数据和临床数据的规范。
“量变到质变”--每一个科研数据库都是一个数据银行
在我看来,每一个科研数据库都可以是一个数据银行,关键要做好数据的积累,让数据“从量变到质变”。那么,如何做好临床肿瘤数据库的建设呢?再次分享一些经验给大家:
首先要做好提前谋划,要把所有肿瘤病例都纳入科研数据库,让数据的颗粒度尽量细化;然后做数据整合,回顾性研究与前瞻性研究数据尽量录入同一数据库;再进行统一随访,就是把随访工作集中管理,关注院内院外信息的收集与汇总;最后要做好多方协作,与数据公司、科研服务公司紧密合作,互惠互利。
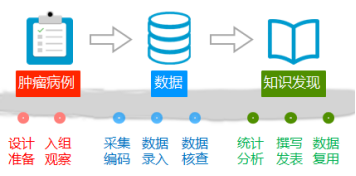
我们要学会“营造自己的数据银行,积累科研财富”。营造临床数据银行主要有三个建设阶段:第一个阶段是“设计准备”、“入组观察”,需要根据肿瘤病例完成;第二个阶段是“采集编码”、“数据录入”、“数据核查”等,要根据采集的数据完成;第三个阶段是“统计分析”、“撰写发表”、“数据复用”,也就是最终的“知识发现”!我们80%的时间都花在了数据预处理上,因为数据预处理很重要,它可以避免“Garbage in, garbage out”的发生。
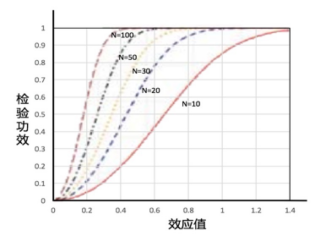
同时,营造数据银行也离不开临床研究中心之间的数据合作,因为数据量越大,它所反映的问题才更可信。从下图可以看出,样本量越大,检验功效越好,越倾向于发现事物之间的差异。例如,美国broad研究院的基因研究人员曾做过一项研究,发现当样本量是3,500时,可能无法发现遗传变异;当样本量为10,000时,只能识别细微遗传变异;而当样本量达到35,000时,统计学上的意义便突然凸显出来了。因此,不同临床研究中心之间的数据合作非常重要。
最后,简单介绍一下我们科室所使用的数据管理系统(craybter科研宝)的功能特点,这款系统主要有几个优点:首先数据采集比较简单,它支持HIS数据的导出与导入,数据源管理比较好;其次,这个系统重视数据的编码规范,并且支持国际化的最新标准,如ICD10、ICD-O-3、AJCC、CTCAE等;该系统还建立了科室的数据质控逻辑体系和人性化的随访管理和提醒功能,包括自定义的随访流程和随访问卷;同时,该数据管理系统还支持科室多个课题的统一管理与多维度查询统计分析。因此,这款系统对我们营造“数据银行”提供了巨大的帮助!
.jpg)
.jpg)
方维佳,浙大一院肿瘤细胞生物治疗中心主任;博士,副主任医师,硕士生导师;香港大学访问学者;美国印第安纳大学 访问学者;国家自然基金面上项目 获得者;浙江省医学会肿瘤学分会委员 ;中国抗癌协会肿瘤化疗营养学组委员 ;中国医促会神经内分泌肿瘤分会委员 ;中国研究型医院学会胰腺病专委会委员 ;中国抗癌协会肿瘤转移专业委员会青委委员;中国研究型医院学会肿瘤MDT专业委员会委员 。






 京公网安备 11010502033352号
京公网安备 11010502033352号